The randomized control trial controversy: Why one size doesn’t fit all and why we need observational studies, case histories, and even anecdotes if we are to have personalized medicine
RandomizedControlTrialIllustration.jpg
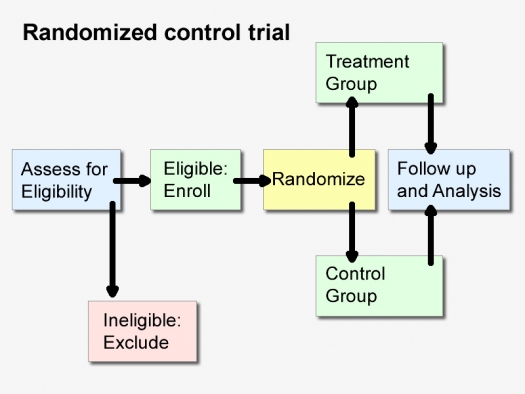
Illustration by FAIM
If the study was not randomized, we would suggest that you stop reading it and go on to the next article.
~ Quote from Evidence-Based Medicine: How to Practice and Teach EBM
Why is it we increasingly hear that we can only know that a new treatment is useful if we have a large randomized control trial, or “RCT,” that has positive results? Why is it so commonly said that individual case histories are “mere anecdotes” and count for nothing, even if a patient, who has had a chronic disease, suddenly gets better with a new treatment after all others failed for years – an assertion that seems, to many people, to run counter to common sense?
Indeed, some version of the statement, “only randomized control trials are useful” has become boilerplate during the COVID-19 crisis. It is uttered as though it is self-evidently the mainstream medical position. When other kinds of studies come out, we are told they are “flawed,” or “fatally flawed,” if not RCTs (especially if the commentator doesn’t like the result; if they like the result, not so often). The implication is that the RCT is the sole reliable methodological machine that can uncover truths in medicine, or expose untruths. But if this is so self-evident, why then, do major medical journals continue to publish other study designs, and often praise them as good studies, and why do medical schools teach other methods?
They do because, as extraordinary an invention as the RCT is, RCTs are not superior in all situations, and are inferior in many. The assertion that “only the RCTs matter” is not the mainstream position in practice, and if it ever was, it is fading fast, because, increasingly, the limits of RCTs are being more clearly understood. Here is Thomas R. Frieden, M.D., former head of the CDC, writing in the New England Journal of Medicine, in 2017, in an article on the kind of thinking about evidence that normally goes into public health policy now:
Although randomized, controlled trials (RCTs) have long been presumed to be the ideal source for data on the effects of treatment, other methods of obtaining evidence for decisive action are receiving increased interest, prompting new approaches to leverage the strengths and overcome the limitations of different data sources. In this article, I describe the use of RCTs and alternative (and sometimes superior) data sources from the vantage point of public health, illustrate key limitations of RCTs, and suggest ways to improve the use of multiple data sources for health decision making. … Despite their strengths, RCTs have substantial limitations.
That, in fact, is the “mainstream” position now, and it is a case where the mainstream position makes very good sense. The head of the CDC is about as “mainstream” as it gets.
The idea that “only RCTs can decide,” is still the defining attitude, though, of what I shall describe as the RCT fundamentalist. By fundamentalist I here mean someone evincing an unwavering attachment to a set of beliefs and a kind of literal mindedness that lacks nuance – and that, in this case, sees the RCT as the sole source of objective truth in medicine (as fundamentalists often see their own core belief). Like many a fundamentalist, this often involves posing as a purveyor of the authoritative position, but in fact their position may not be. As well, the core belief is repeated, like a catechism, at times ad nauseum, and contrasting beliefs are treated like heresies. What the RCT fundamentalist is peddling is not a scientific attitude, but rather forcing a tool, the RCT, which was designed for a particular kind of problem to become the only tool we use. In this case, RCT is best understood as standing not for Randomized Control Trials, but rather “Rigidly Constrained Thinking” (a phrase coined by the statistician David Streiner in the 1990s).
Studies ask questions. Understanding the question, and its context, is always essential in determining what kind of study, or tool, to use to answer those questions. In the “RCT controversy,” to coin a phrase, neither side is dismissive of the virtues of the RCT; but one side, the fundamentalists, are dismissive of the virtues of other studies, for reasons to be explained. The RCT fundamentalist is the classic case of the person who has a hammer, and thinks that everything must therefore be a nail. The nonfundamentalist position is that RCTs are a precious addition to the researcher’s toolkit, but just because you have a wonderful new hammer doesn’t mean you should throw out your electric drill, screwdriver, or saw.
So let’s begin with a quick review of the rationale for the “randomized” control trial, and their very real strengths, as originally understood. It’s best illustrated by what happens without randomization.
Say you want to assess the impact of a drug or other treatment on an illness. Before the invention of RCTs, scientists might take a group of people with the illness, and give them the drug, and then find another group of people, with the same illness, say, at another hospital, who didn’t get the drug, and then compare the outcome, and observe which group did better. These are called “observational studies,” and they come in different versions.
But scientists soon realized that these results would only be meaningful if those two groups were well matched in terms of illness severity and on a number of other factors that affect the unfolding of the illness.
If the two groups were different, it would be impossible to tell if the group that did better did so because of the medication, or perhaps because of something about that group that gave it an advantage and better outcome. For instance, we know that age is a huge risk factor for COVID-19 death, probably because the immune system declines as we age, and the elderly often already have other illnesses to contend with, even before COVID-19 afflicts them. Say one group was, on average, 60 years old, and all the members got the drug, and the other group was on average 75 years old, and they were the ones that didn’t get the drug. Say that when results were analyzed and compared, they showed the younger group had a higher survival rate.
A naive researcher might think that he or she was measuring “the power of the medication to protect patients from COVID-19 death” but may actually have also been measuring the relative role of youth, in protecting the patients. Scientists soon concluded there was a flaw in that design, because we do not know, with any reasonable degree of confidence, whether the better outcomes were due to age or the medication.
Age, here, is considered a “confounding factor.” It is called a confounding factor, because it causes confusion, because age can also influence the outcome of the study in the group as a whole. Other confounding factors we know about in COVID-19 now include how advanced the illness is at the time of the study, diabetes, obesity, heart disease, and probably the person’s vitamin D levels. But there could easily be, and probably are, many other confounding factors we don’t know, as of yet. There are even potential confounding factors that we suspect play a role, but are not quite certain about: the person’s general physical fitness, the ventilation in their home, and so on.
This is where randomization is helpful. In a randomized control trial, one takes a sufficiently large group of patients and randomly assigns them to either the treatment group, or the nontreatment (“placebo” or sugar pill) control group, for instance. Efforts are made to make sure that apart from the treatment, everything else remains the same in the lives of the two groups. It is hoped that by randomly assigning this large number of patients to either the treatment or nontreatment condition, that each of the confounding factors will have an equal chance of appearing in both groups – the factors we know, such as age, but also mysterious ones we don’t yet understand. While observational studies can, with some effort, match at least some confounding factors we do understand in a “group matched design” (and, for instance, make sure both groups are the same age, or disease severity), what they can’t do is match confounding factors we don’t understand. It is here, that RCTs are generally thought to have an advantage.
With such a good technique as RCTs, one might wonder, why do we ever bother with observational studies?
There are a number of situations in medicine in which observational studies are obviously superior to randomized control trials (RCTs), such as when we want to identify the risk factors for an illness. If we suspected that using crack cocaine was bad for the developing brains of children, it would not be acceptable to do an RCT (which would take a large group of kids, and randomly prescribe half of them crack cocaine and the other half a placebo and then see which group did better on tests of brain function). We would instead follow kids who had previously taken crack, and those who never had, in an observational study, and see which group did better. All studies ask questions, and exist in a context, and the moral context is relevant to the choice of the tool you use to answer the question. That is Hippocrates 101: Do no harm.
Now, you might say that a study of risk factors is very different from the study of a treatment. But it is not that different. There can be very similar moral and even methodological issues.
In the 1980s, quite suddenly, clinicians became aware that infants were dying, in large numbers, in their cribs, for reasons that couldn’t be explained, and a new disorder was discovered, sudden infant death syndrome, or SIDS, or “crib death.” Some people wondered if parents were murdering their children, or if it was infectious, and many theories abounded. A large observational study was done in New Zealand that observed and compared factors in the lives of the infants who died and those who didn’t. The study showed that the infants who died were frequently put to sleep on their tummies. It was “just” an observation. But on that basis alone, it was suggested that having infants sleep on their backs might be helpful, and that parents should avoid putting their infants on their fronts in their cribs. Lo and behold, the rates of infant death radically diminished – not completely, but radically. No sane caring person said: “We should really do an RCT, rule out confounding factors, and settle this with greater certainty, once and for all: All we have to do is randomly assign half the kids to be put to bed on their tummies and the other half on their backs.” That would have been unconscionable. The evidence provided by the observational study was good enough.
Again, all studies have a context and are a means to answering questions. The pressing question with SIDS was not: How can we have absolute certainty about all the causes of SIDS? It was: How can we save infant lives, as soon as possible? In this case, the observational study answered it well.
The SIDS story is a case where we can see how close, in moral terms, a study of risk factors and a study of a new treatment can be in a case where the treatment might be lifesaving. Putting children on their tummies is a risk factor for SIDS. Putting them on their backs is a treatment for it. The moral issue of not harming research subjects by subjecting them to a likely risk is clear.
Similarly, withholding the most promising treatment we have for a lethal illness is also a moral matter. That is precisely the position taken by the French researchers who thought that hydroxychloroquine plus azithromycin was the most promising treatment known for seriously ill COVID-19 patients, and who argued that doing an RCT (which meant withholding the drug from half the patients) was unconscionable. RCT fundamentalists called their study “flawed” and “sloppy,” implying it had a weak methodology. The French researchers responded, in effect saying, we are physicians first; these people are coming to us to help them survive a lethal illness, not to be research subjects. We can’t randomize them and say to half, sorry, this isn’t your lucky day today, you are in the nontreatment group.
There are other advantages to observational studies in assessing new treatments. They are generally lower in cost than RCTs, and can often be started more quickly, and published more rapidly, which helps when information is needed urgently, as in a novel pandemic when little is understood about the illness. (RCTs, in part because of the moral issues, take longer to get ethics approval.) Observational studies are also easier to conduct at a time when patients are dying in high numbers, and hospital staff is overwhelmed, trying to keep people alive. They can involve looking back in time, to make use of observations in the medical chart. In such cases, it is crucial that the initial observations about how patients responded to the medications and treatments that the staff had on hand is documented, in as systematic as way as is possible, because there might be clues and nuggets as to what worked.
Exclusion Criteria: Do RCTs Study Real-World Patients?
But there are also problems at the conceptual heart of the RCT. Often the RCT design sees “confounding factors” not simply as something that has to be balanced between the treatment and no-treatment groups by randomization, but eliminated at the outset. For a variety of reasons, includinga wish to make interpretation of final results more certain, they aggressively eliminate known confounding factors before the study starts, by not letting patients with certain confounding factors get into the study in the first place. They do this by often having a lot of what are called “exclusion criteria,” i.e., reasons to exclude or disqualify people from entering the study.
Thus, RCTs for depression typically study patients who only have depression and no other mental disorders, which might be confounding factors. So, they usually study people who are depressed but who are not also alcoholic, not on illicit drugs, and who don’t have personality disorders. They also tend to exclude people who are actively suicidal (because if they are, they might not complete the expensive study, and some people think it is unethical to give a placebo to a person in acute risk of killing themselves). There are many other reasons given for different exclusions, such as a known allergy to a medication in the study.
But here’s the problem. These exclusions often add up until many, maybe even most, real-world depressives get excluded from such a study. So, the study sample is not representative of real-world patients. Yet this undermines the whole purpose of a research study “sample” in the first place, which is to test a small number of people (which is economical to do), and then extrapolate from them on to the rest of the population. As well, many studies of depression and drugs end up looking at people who are about as depressed as a college student who just got a B+ and not an A on a term paper. This is why many medications (or short-term therapies) end up doing well in short-term studies, but the patients relapse.
If you are a drug company (which pay for most of these studies) and you’re testing your new drug, exclusion criteria can be made to work in favor of making your drug appear more powerful than it really is, if sicker patients are eliminated. (This is a good trick, especially if your goal of making money from the drug is your first priority.)
This isn’t a matter of conjecture. This question of whether RCTs, in general, are made up of representative samples has been studied. An important review of RCTs found that 71.2% were not representative of what patients are actually like in real-world clinical practice, and many of the patients studied were less sick than real-world patients. That, combined with the fact that many of the so-called finest RCTs, in the most respected and cited journals, can’t be replicated 35% of the time when their raw data is turned over to another group that is asked to reconfirm the findings, shows that in practice they are far from perfect. That finding – that something as simple as the reanalysis of the numbers and measurements in the study can’t be replicated – doesn’t even begin to deal with other potential problems in the studies: Did the author ask the right questions, collect appropriate data, have reliable tests, diagnose patients properly, use the proper medication dose, for long enough, and were their enough patients in it? And did they, as do so many RCTs, exclude the most typical and the sickest patients?
Note, other study designs also have exclusion criteria, but they often are less problematic than in RCTs for reasons to be explained below.
The Gold Standard and the Hierarchy of Evidence
So, why is it we also hear that “RCTs are the gold standard,” and the highest form of evidence in the “hierarchy of evidence,” with observational studies beneath them, and case histories, at the bottom, and anecdotes beneath contempt?
There are several main reasons.
The first you just learned. It had been believed that RCTs were a completely reliable way to study a treatment given to a small sample of people in a population, see how they did, and then one could extrapolate those findings to the larger population. But that was just an assumption, and now that we have learned the patients studied are too often atypical, we have to be very careful about generalizing from an RCT. This embarrassment is a fairly recent finding that has yet to be taken fully into account by those who say RCTs are the gold standard.
The second reason has to do with the fundamentalists relying on outdated science, which argued that RCTs are more reliable in their quantitative estimates of how effective treatments are because they randomize and rule out confounding factors.
But a scientist who wanted to know if RCTs, as a group, were universally better and more reliable than observational studies at truth-finding would actually study the question scientifically, and not just assert it. And, in the 1980s, Chalmers and others did just that, examining studies from the 1960s and 1970s. They found that in the cases where both RCTs and observational studies had been done on the same treatment, the observational studies yielded positive results 56% of the time, whereas blinded RCTs did so only 30% of the time. It thus seemed that observational studies probably exaggerated how effective new treatments were.
Three other reviews of comparisons of observational and RCT study outcomes showed this same difference, and so researchers concluded that RCTs really were likely better at detecting an investigator’s bias for the treatment being studied, and hence more reliable. Since many scientific studies of drugs were paid for by drug companies that manufactured those drugs, it was not a surprise that the studies would have biases. These reviews formed much of the basis for RCT fundamentalism.
Just because an RCT is performed and published is no reason to assume it doesn’t exaggerate efficacy.
But here’s the problem: These were reviews of studies that were done in the 1960s and 1970s. Once the observational study researchers became aware of the problem, they upped their game, and improved safeguards.
In 2000, new reviews comparing the results from hundreds of RCTs and observational studies in medicine that had been conducted in the 1990s were conducted by scientists from Yale and Iowa College of Medicine. They found that the tendency of observational studies to suggest better results in treatments had now disappeared. They now got similar results to RCTs. This was an important finding, but it has not been sufficiently integrated into the medical curriculum.
There is another reason we hear about RCTs. As RCTs became the type of study favored by regulatory bodies to test new drugs, they rose to prominence, and drug companies upped their game and learned many ingenious ways to make RCTs exaggerate the effectiveness of the drugs they are testing.
Entire books have been written on this subject, an excellent one being Ben Goldacre’s Bad Pharma: How Drug Companies Mislead Doctors and Harm Patients. Since, to bring a drug to market requires only two RCTs showing the drug works, these techniques include doing many studies but not publishing the ones that don’t show good results. But there are sneakier techniques than making whole studies with negative outcomes go missing. There are ways to publish studies but hide embarrassing data; publish the good data in well-known journals and the negative findings in obscure journals; not study short-term side effects; almost never study, or ask about, long-term side effects; or play with measuring scales, so that patients appear to achieve statistically meaningful benefits which make no clinical difference. If you do a study that gives you a bad outcome on your key measure, don’t report that, just find some small outcome that was in your favor and retroactively change the goal of the study, to report that benefit and that alone. Make researchers and subjects sign gag clauses and nondisclosures. Have the drug companies ghostwrite the papers, make up the tables, and get academics, who never see the raw data sign them. This is routine.
The list goes on, and those tricks have often been used, successfully, to gain approval for drugs. Becoming very familiar with these ruses can save lives, because in a pandemic, new drugs will earn Big Pharma billions because the illness is so widespread, and they have a large playbook to draw from. Once two RCTs are selected from the many done to take the drug forward, the propaganda campaign begins, and as Goldacre shows, drug companies spend twice as much on marketing as they do on research. So, to repeat, just because an RCT is performed and published is no reason to assume it doesn’t exaggerate efficacy.
One group of studies, though, that don’t often play by these corrupt rules are RCTs done on already generic drugs, because they are off-patent, and there is really very little money to be made in them. In these cases, when a drug company has a generic rival to what might be a big money maker, there are ways of making that generic look bad. If the generic takes four weeks to work, test your drug against it, in a three-week study (the placebo effect for your drug won’t have worn off yet). If a vitamin is threatening your drug, test your drug against it, but use the cheapest version, in a dose that is too low. It’s an RCT, that’s all that matters.
Despite all this, advocates of RCTs still teach that, all else being equal, RCTs are always more reliable, and teach this by cherry-picking well-known cases where RCTs were superior to observational studies, and ignore cases where observational studies have been superior, or at least the better tool for the situation. They take the blunt position that “RCTs are better than observational studies,” and not, the more reasonable, accurate, and moderate, “All else being equal, in many, but not all situations, RCTs are better than observational studies.”
The phrase, “all else being equal,” is crucial, because so often all else is not equal. Simply repeating “RCTs are the gold standard of evidence-based medicine” implies to the naive listener that if it is an RCT then it must be a good study, and reliable, and replicable. It leaves out that most studies have many steps in them, and even if they have a randomization component, they can be badly designed in a step or two, and then lead to misinformation. Then there is the very uncomfortable fact that, so often, RCTs can’t even be replicated, and so often contradict each other, as anyone who has followed RCTs done on their own medical condition often sadly finds out. A lot of this turns out to be because they have many steps, and because Big Pharma is so adept now at gaming the system. Like gold, they turn out to be valuable but also malleable. A lot of the problem is that patients differ far more than these studies concede, and these complexities are not well addressed in the study design.
The Hierarchy-of-Evidence Notion Does Harm, Even to RCTs
One of the peculiar things about current evidence-based medicine’s love affair with its “hierarchy of evidence” is that it is still proceeding along, ignoring the implications of the scientifically documented replication crisis. True, the fact there is a replication crisis is now widely taught, and known about, but to the fundamentalists, it is as though that “crisis” doesn’t require that they reexamine basic assumptions. The replication crisis is compartmentalized off from business as usual and replaced with RCT hubris.
The irony is that the beauty of the RCT is that it’s a technique designed to neutralize the effects of confounding factors that we don’t understand on a study’s outcome, and thus it begins in epistemological humility. The RCT, as a discovery, is one of humanity’s wonderful epistemological achievements, a kind of statistical Socrates, which finds that wisdom begins with the idea, “whatever I do not know, I do not even suppose I know” (Apology, 21d).
But that beautiful idea, captured by a fundamentalist movement, has been turned on its head. The way the RCT fundamentalist demeans other study designs is to judge all those designs by the very real strengths of RCTs. This exaggeration is implicit in the tiresome language they use to discuss them: The RCTs are the “gold standard,” i.e., against which all else is measured, and the true source of value. Can these other designs equal the RCT in eliminating confounders? No. So, they are inferior. This works, as long as one pretends there are no epistemological limitations on RCTs. The problem with that attitude is, it virtually guarantees that the RCT design will not be improved, alas, because improved RCTs would benefit everyone. In fact, RCTs would be most quickly improved if the fundamentalists thought more carefully about the benefits of other studies, and tried to incorporate them, or work alongside them in a more sophisticated way. That is another way of saying we need the “all available evidence” approach.
The Case History and Anecdotes
Also disturbing, and, odd, actually, is the belittling of the case history as a mode of making discoveries, or what it has to offer science as a form of evidence. In neurology, for instance, it was the individual cases, such as the case of Phineas Gage, that taught us about the frontal lobes, and the case of H.M., that taught us about the role of memory, two of the most important discoveries ever made in brain science.
Here’s how the belittlement goes. “Case histories are anecdotes, and the plural of anecdote is not data, it is just lots of anecdotes.”
First of all, case histories are not anecdotes. An anecdote, in a medical text, is usually several sentences, at most a paragraph, stripped of many essential details, usually to make a single point, such as “a 50-year-old woman presented with X disease, and was treated with Y medication, for 10 days, and Figure 7 shows her before and after X-rays, and the dramatic improvement.” In that sense, an anecdote is actually the opposite of a case history, which depends on a multiplicity of concrete, vivid details.
A case history (particularly in classic neurology or psychiatry) can run for many pages. It is so elaborated because it understands, as the Canadian physician William Osler pointed out: “The good physician treats the disease; the great physician treats the patient who has the disease.” And who that patient is – their strengths, weaknesses, their other illnesses, other medications, emotional supports, diet, exercise habits, bad habits, genetics, previous treatment histories, all factor into the result. To practice good medicine, you must take it all into account, understanding that the patient is not any one of these details, but a whole who is more than the sum of the parts. Thus, true patient-centered medicine necessarily aspires toward a holistic approach. So, a case history is a concrete portrait of a real person, not an anecdote; and it is vivid, and the furthest thing possible from an abstract data set.
A typical RCT describes several data points about hundreds of patients. A typical case history describes perhaps hundreds of data points about a single patient. It’s not inferior, it’s different. The case history is, in fact, a technology, albeit an old one, set in language (another invention, we forget) and its structure (what is included in the case history, such as descriptions of the patient’s symptoms, objective signs, their subjective experiences, detailed life history, what makes the illness better, what worse, etc.) was developed over centuries.
Even anecdotes have their place. We often hear methodologists say, when a physician claims he or she gave a patient a particular medication, or supplement, or treatments, and they got better, “that that proves nothing. It is just an anecdote.” The problem is in the word “just.” Something doesn’t become meaningless, or a nonevent because a scientist adds the word “just” before it. That word really says nothing about the anecdote and a lot about the speaker’s preference for large number sets.
But anecdotes are very meaningful, too, and not just when lives are changed by a new treatment for the first time. This dismissive indifference to anecdotes turns out to be very convenient, for instance, for drug companies. If you are a physician, and you give a patient who had perfectly good balance an antibiotic, like gentamicin, and she suddenly loses all sense of balance because it injured her balance apparatus, the drug maker can say that is “just” an anecdote. It doesn’t count. And in fact, it is a fairly rare event. But it is by just such anecdotes that we learn of side effects, in part because (as I said above) most RCTs for new drugs don’t ask about those kinds of things, because they don’t want to hear the answer.
If we are to be honest, evidence-based medicine is, in large part, still aspirational. It is an ideal.
That’s why the approach I take – and I think most trained physicians with any amount of experience and investment in their patients’ well-being also take – might be called the all-available-evidence approach. This means, one has to get to know each of the study designs, their strengths, and their weaknesses, and then put it all together with what one is seeing, with one’s own eyes, and hearing from the particular patient who is seeking your care. There are no shortcuts.
One of the implications of this approach in the current COVID-19 situation is that we cannot simply, as so many are insisting, rely only on the long-awaited RCTs to decide how to treat COVID-19. That is because physicians in the end don’t treat illnesses, they treat patients with illnesses, and these patients differ.
The RCTs that are on the way may recommend, in the end, one medication as “best” for COVID-19. What does that mean? That it is best for everyone? No, just that in a large group, it helped more people than other approaches.
That information – which medication is best for most people, is very useful if you are in charge of public health for a poor country and can only afford one medication. Then you want the one that will help most people.
But if you are ordering for a community that has sufficient funds for a variety of medications, you are interested in a different question: What do I need on hand to cover as many sick people as possible, and not just those who benefit from medication X which helps most, but not all people? Even if a medication helps, say, only 10% of people, those will be lives saved, and it should be on hand. A medication that helped so few might not even have been studied, but if the others failed, it should be tried.
A physician on the frontline wants, and needs, access to those medications. He or she asks, “What if my patient is allergic to the medication that helps most people? Then, what others might I try?” Or, “What if the recommended medication is one that interacts negatively with a medication that my patient needs to stay alive for their non-COVID-19 condition?”
There are so many different combinations and permutations of such problems – and hardly any of them are ever studied – that only the physician who knows the patient has even a chance of making an informed decision. They are the kinds of things that arise on physician chat lines, that ask questions to 1,000 online peers like, “I have a patient with heart disease, on A, B, and C meds, and kidney disease on D, who was allergic to the COVID-19 med E. Has anyone tried med F, and if so, given their kidney function, should I halve the dose?”
Evidence-based medicine hasn’t studied some of the most basic treatments with RCTs or observational studies, never mind these kinds of individual complexities. So, the most prudent option is to allow the professional who knows the patient to have as much flexibility as possible and access to as many medications as possible. If we are to be honest, evidence-based medicine is, in large part, still aspirational. It is an ideal. Clinicians need latitude, and patients assume they have it. But now the RCT fundamentalists are using the absence of RCTs for some drugs to restrict access to them. They have gone too far. This is epistemological hubris, at the expense of lives, and brings to mind the old adage, “Absence of evidence is not evidence of absence.” As long as we’ve not got the best studies for all conceivable permutations, medicine will remain both an art and a science.
So, does conceding as much and giving the clinician latitude mean I don’t believe in science?
“Believe,” you say?
That is not a scientific word. Science is a tool. I don’t worship tools. Rather, I try to find the right one for the job. Or, for a complex task, which is usually the case in medicine – especially since we are all different, and all complex – the right ones, plural.
Medicine’s Fundamentalists was originally published in Tablet Magazine, and is reprinted with permission.

